TensorFlow: saving/restoring and mixing multiple models
Via: https://blog.metaflow.fr/tensorflow-saving-restoring-and-mixing-multiple-models-c4c94d5d7125
TensorFlow: saving/restoring and mixing multiple models
Before going any further, make sure you read the very small primer i made on Tensorflow here
Why start with those informations? Because, it is of tremendous importance to understand what can be saved at the different level of your code to avoid messing around cluelessly…
How to actually save and load something
The saver object
Any interactions with your filesystem to have persistent data through different sessions can be handled with the Saver object. The constructor allows you to control 3 things:
- The target: This is used in case of a distributed architecture to handle computation. You can specify which TF server or ‘target’ you want to compute on.
- The graph: the graph you want the Session to handle. The tricky things here for beginners, is the fact that there is always a default Graph in TF where all operations are set by default, so you are always in a “default Graph scope”.
- The config: You can use ConfigProto to configure TF. Check the linked source for more details.
The Saver, can handle the saving and loading (called restoring) of your Graph metadata and your Variables data. The only things it needs to know are: which Graph and Variables are we talking about?
By default, the Saver will handle the default Graph and all its included Variables, but you can create as much Savers as you want to control any graph or subgraph of variables you want. Here is an example:
If you look at your folder, it actually creates 3 files per save call and a checkpoint file, i’ll go into more details about this in the annexe. You can go on just by understanding that weights are saved into .chkp.data files and your graph and metadata are saved into .chkp.meta files.
Restoring operations and other meta data
One important information is the fact that the Saver will save any metadata associated with your Graph. It means that loading a meta checkpoint will also restore all empty variables, operations and collections associated with your Graph (for example, it will restore training optimizer).
When you restore a meta checkpoint, you actually load your saved graph in the current default graph. Now you can access it to load anything inside like a tensor, an operation or a collection.
Restoring the weights
Remember that actual real weights only exists within a Session. It means that the “restore” action must have access to a session to restore weights inside a Graph. The best way to understand the restore operation is to see it simply as a kind of initialisation.
Using a pre-trained graph in a new graph
Now that you know how to save and load, you can probably figure out how to do it. Yet, their might be some tricks that could help you go faster.
- Can the output of one graph be the input of an other graph ?
Yes, but there is a drawback to this: I don’t know yet a way to make the gradient flow easily between graphs, as you will have to evaluate the first graph, get the results and feed it to the next graph.
This can be ok, until you need to retrain the first graph too. in that case you will need to grab the inputs gradients to feed it to the training step of your first graph…
- Can I mix all of those different graph in only one graph?
Yes, but you must be careful with namespace. The good point, is that this method simplifies everything: you can load a pretrained VGG-16 for example, access any nodes in the graph, plug your own operations and train the whole thing!
If you only want to fine-tune your own nodes, you can stop the gradients anywhere you want to avoid training the whole graph.
Annexe: More about the TF data ecosystem
We are talking about Google here, and they mainly use in-house built tools when dealing with their work, so it will be no surprise to discover that data are saved in the ProtoBuff format.
Protocol buffers
Protocol Buffers often abreviated Protobufs is the format use by TF to store and transfer data efficiently.
I don’t want to go into details but think about it as a faster JSON format that you can compressed when you need to save space/bandwidth for storage/transfer. To recapitulate, you can use Protobufs as:
- An uncompressed, human friendly, text format with the extension .pbtxt
- A compressed, machine friendly, binary format with the extension .pb or no extension at all
It’s like using JSON in your development setup and when moving to production, compressing your data on the fly for efficiency. Many more things can be done with Protobufs, if you are interested check the tutorials here
Neat trick: All operations dealing with protobufs in tensorflow have this “_def” suffix that indicate “protocol buffer definition”. For example, to load the protobufs of a saved graph, you can us the function:tf.import_graph_def. And to get the current graph as a prtobufs, you can use:Graph.as_graph_def().
Files architecture
Getting back to TF, when you will save your data, you will end up with 5 different type of files:
- A “checkpoint” file
- An “events” file
- A “textual protobufs” file
- Some “chkp” files
- Some “meta chkp” files
Let’s take a break here. When you think about it, what could potentially be saved when you are doing machine learning? You can save the architecture of your model and the learned weights associated to it. You might want to save some training characteristics like the loss and accuracy of your model while training or event the whole training architecture. You might want to save hyper parameters and other operations to restart training later or replicate a result. This is exactly what TensorFlow does.
The trio of checkpoint files type are here to store the compressed data about your models and its weights.
- The checkpoint file is just a bookkeeping file that you can use in combination of high-level helper for loading different time saved chkp files.
- The meta chkp files hold the compressed Protobufs graph of your model and all the metadata associated (collections, learning rate, operations, etc.)
- The chkp files holds the data (weights) itself (this one is usually quite big in size).
- The pbtxt file is just the non-compressed Protobufs graph of your model if you want to do some debugging.
- Finally, the events file store everything you need to visualise your model and all the data measured while you were training, with TensorBoard. This has nothing to do with saving/restoring your models itself.
Let’s have a look at the following screen capture of a result folder:
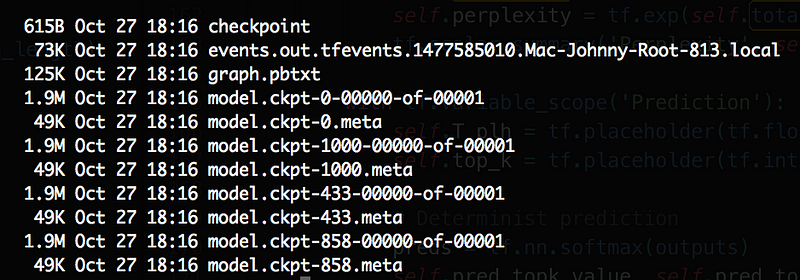
- The model has been saved 3 times at steps 433, 858, 1000. Why those numbers looks like random? Because i’ve been saving my model every S seconds and not every T iterations.
- chkp files are a lot heavier than the meta chkp files which was expected as they are containing the weights of our model
- The pbtxt file is a little bit bigger than the meta chkp files, again: it is expected as the non-compressed version!
TF comes with multiple handy helpers like:
- Handling different checkpoints of your model in time and iteration. This can be a lifesaver if one of your machine break before the end of a training.
- Separating weights and metadata. You can share a model without its training weight easily.
- Saving metadata allow you to be sure to reproduce a result or continue a training etc.
To dive even more in this: https://www.tensorflow.org/versions/r0.11/how_tos/tool_developers/index.html
TensorFlow best practice series
This article is part of a more complete series of articles about TensorFlow. I’ve not yet defined all the different subjects of this series, so if you want to see any area of TensorFlow explored, add a comment! So far I wanted to explore those subjects (this list is subject to change and is in no particular order):
- A primer
- How to handle shapes in TensorFlow
- TensorFlow saving/restoring and mixing multiple models (this one :) )
- How to freeze a model and serve it with a python API
- TensorFlow howto: a universal approximator inside a neural net
- How to optimise your input pipeline with queues and multi-threading
- Mutating variables and control flow
- Architecture: how to separate my code in files and folders so my work is easy to understand and reusable.
- How to handle preprocessing with TensorFlow.
- How to control the gradients to create custom back-prop with, or fine-tune my models.
- How to monitor my training and inspect my models to gain insight about them.,
Note: TF is evolving fast right now, those articles are currently written for the 1.0.0 version.
References
- http://stackoverflow.com/questions/38947658/tensorflow-saving-into-loading-a-graph-from-a-file
- http://stackoverflow.com/questions/34343259/is-there-an-example-on-how-to-generate-protobuf-files-holding-trained-tensorflow?rq=1
- http://stackoverflow.com/questions/39468640/tensorflow-freeze-graph-py-the-name-save-const0-refers-to-a-tensor-which-doe?rq=1
- http://stackoverflow.com/questions/33759623/tensorflow-how-to-restore-a-previously-saved-model-python
- http://stackoverflow.com/questions/34500052/tensorflow-saving-and-restoring-session?noredirect=1&lq=1
- http://stackoverflow.com/questions/35687678/using-a-pre-trained-word-embedding-word2vec-or-glove-in-tensorflow
- https://github.com/jtoy/awesome-tensorflow
Comments
Post a Comment